Octolooks
Single, serial or feed scraper. Which task type should be used in which case? For the right and efficient use, start by selecting the type of task that best suits your needs.
Scrapes is a WordPress scraper plugin that lets you easily pull content automatically with visual selector, without having any programming skills to your own website from such sites. Scrapes developed to meet different scraping needs from the simplest to the most advanced; consists of 3 different task type options, namely “single”, “serial” or “feed”.
Although they share some common settings, these task types are different from each other with their purpose of use. First the required fields “request options” in particular, to be filled in order to start scraping varies according to the selected task type.
Single Scraper
Single scraper task type; as it is the easiest task type to use, it is mostly used for simple and small web scraping operations. Taking a single page in the source site as a whole to your own website or pulling a small content on this site to embed it in any area on your website of your choice is the most accurate example of the use of this type of task.
Since the purpose of this type of task is to get content from only one page; filling the source URL field with the other required fields which are also common to other task types too is sufficient to create a scraper task of this type.
Source URL: The web address of the page that belongs to the source site you want to extract content into your site from being either starts with http or https. The entered web address is loaded into the visual selector and ease of use provided for configuring settings that require XPath value.
After the created scraper task runs successfully, the new content is generated on your site consists of a new post grabbed from the source site. You can use this post as is, edit it manually and publish later, or keep it up-to-date by taking advantage of the “Schedule” feature continuously.
Embed scraped content in an area on your site
Instead of pulling the entire content of the source site as a post, you might want to take a small portion into your site to embed it in an area of your choice. In this case, you can create a single scraper type task by using the visual selector to identify the content section you want to pull and you can embed the captured content in different areas of your website, such as post, page, sidebar with “Post Content Shortcodes” a third party free WordPress plugin. The steps that you must follow to perform this operation are as follows.
- Sign in to the WordPress administration panel (wp-admin).
- From the left navigation, click on “Scrapes » Add New” link.
- Select “Single” scraper as the task type.
- Fill in the Source URL field, define the content you want to take by using the visual selector in the “Content” settings field, configure the other settings, and save the task by clicking the “Save” button.
- After the task runs and completes successfully, click “Posts » All Posts” link from the left navigation and in order to close the accessibility of the post created for visitors edit them as, “Draft” for embedding purpose only. (You can skip this step if you have selected the post status option “Draft” while creating the task.)
- Install Post Content Shortcodes WordPress plugin and activate.
- In the post, page or text widget you want to see the embedded content, add the post ID in [post-content id=1] format as a short code.
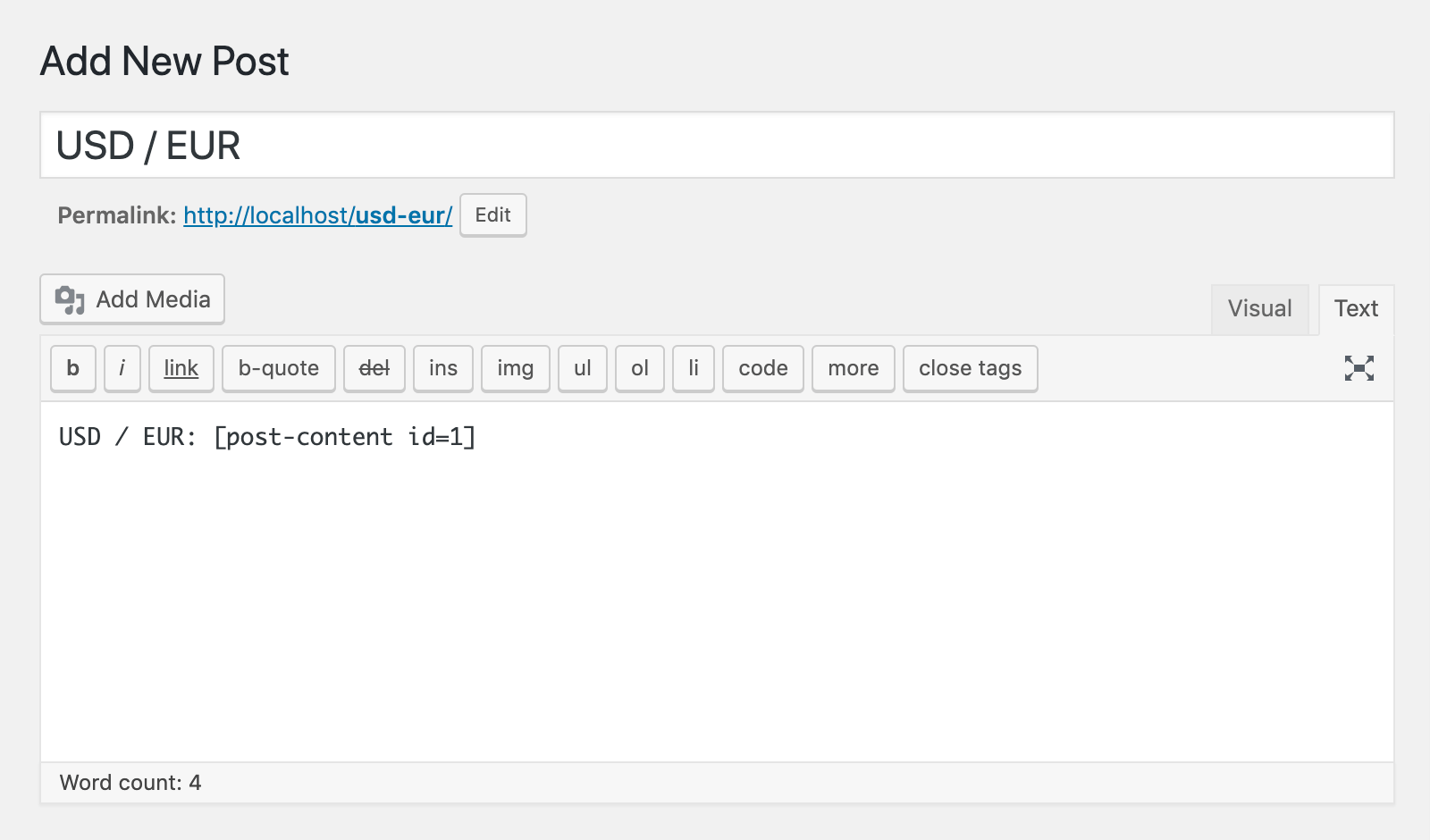
If you wish, you can combine multiple scraped contents from various sources and different scraper tasks by adding their shortcodes into one single post. You can also select the “Run frequency” settings of the scraper tasks that make these contents to be updated in “Every hour” or a bit more frequent period so that the post that has the merged content can be kept up-to-date continuously. Some examples of the use of this method are as follows.
- Collection of different exchange rates in a single post.
- Collection of weather conditions of different locations in a single post.
- Collection of sales data of different products in a single post (Product comparison).
- Collection of price options on different sites for a particular product to be updated in a single post (Price comparison).
Serial Scraper
Serial scraper task type; has more advanced settings than other task types, and is often used for complex and comprehensive web scraping. Collecting all content in a source site with multiple pages to your own site as a WordPress auto post plugin, is one of the most accurate examples of the use of this task type.
Resource sites which consist of multiple pages; have a list of “pagination” pages that provide navigation between pages and excerpts that leads to the detail page when clicked. The links in these listing pages, which can be of different types, such as category, search result, gallery or sitemap, are automatically followed; filling the “Source URL”, “Post Item” and “Next Page Item” fields along with the other common required fields of other types of tasks is enough to create a this type of scraper task.
Source URL: It is the field that needs to be entered with the web address of source site’s listing pages that you want to copy content to your site from starting with “http” or “https”. This entered web address is loaded into the visual selector and ease of use is provided for configuring the settings that require XPath value.
Post Item: The XPath value that belongs to the first summary content in the listing page of the source site that also has a link to the detail page when clicked is the field that needs to be defined. In the listing page, links of the same type with this value are automatically detected. If the links to the other summary contents are not in the same container in a similar format, the “exact match only” feature is activated to identify similar links on the listing page.
Next Page: This field can be defined in two different options, either “Select from source “or “Enter URL parameter”. “Select from source”; is the required field where the XPath value of the last link of navigation in the source page in the “pagination” format should be defined, when clicked it also leads to the next listing page to indicate the continuation of the summary of the contents in the source site.
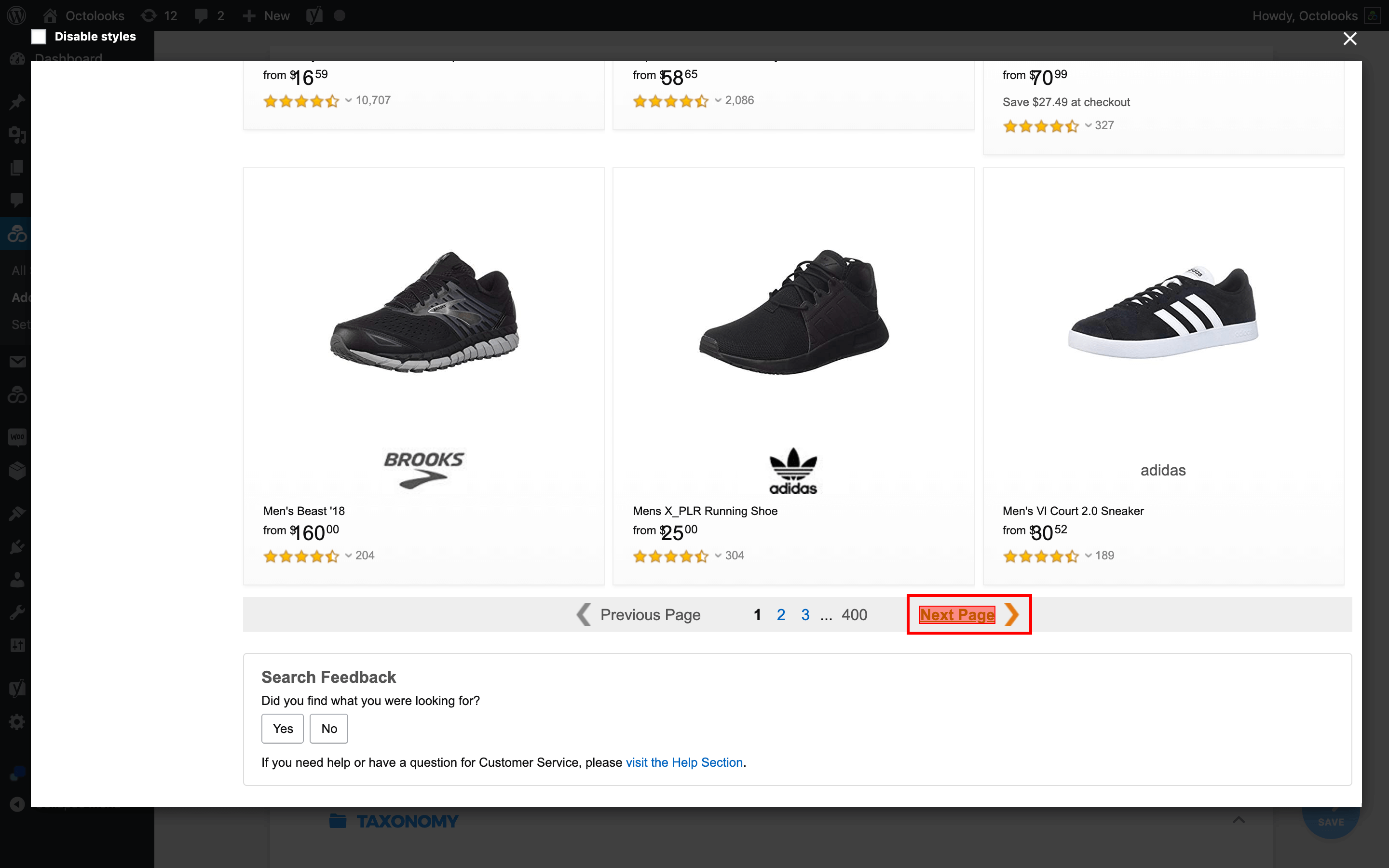
If this link to be defined is not available on the source page, in order to find the next listing pages by using url parameters in ?page=1 format, after “Enter URL parameter” option is selected the new URL parameter is added and the name, initial value and the increment amount are defined. More than one parameter can be added if needed. There is no need to define “Next Page” field if the desired content is available on a one single listing page.
After the created scraper task runs successfully, the content on your site consists of posts pulled from the source site. You can use these posts as they are, edit and publish them manually, or keep up to date by taking advantage of “Schedule” feature.
Feed Scraper (WP RSS Aggregator)
Feed scraper task type; is mainly used for scraping operations on feeds in “RSS” or “Atom” format, which is provided by news sites, blogs and podcasts to sync with the most current content. Grabbing all content in the source feed into different posts on your own site is one of the most accurate examples of the use of this task type. In addition, where the source site is not suitable for the serial scraper task type, the feed scraper task type is used as an alternative. This task type is also known as WP RSS Aggregator.
Feeds; because they consist of a limited number of brief contents that can be automatically detected without the “Post Item” definition and which do not require “Next Page” definition by redirecting to the detail page when clicked; filling the “Source URL” field with the required fields common to other task types is enough to create a this type of scraper task. The “Detect from feed” option in “Title”, “Content”, “Featured Image”and “Date” fields takes the summary content in the source feed into the corresponding area as well as; “Select from source” option is selected to extract the contents of the detailed pages they are referring to by defining XPath values in the relevant field instead of these summary contents.
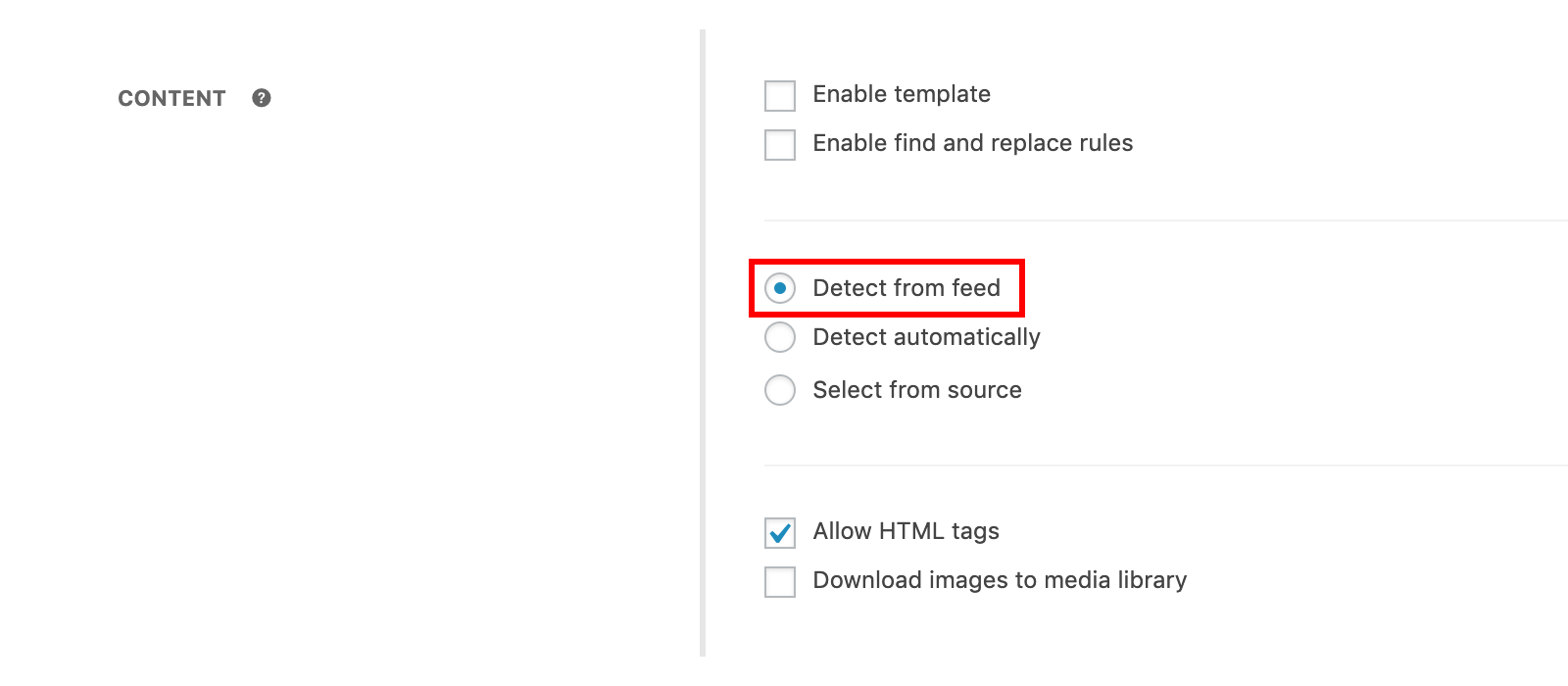
Source URL: The web address that starts with “http” or “https” of the source feed you want to gather content to your own site is the field that needs to be entered. This entered web address is loaded into the visual selector and when “Select from source” option is selected ease of use is provided for configuring the settings that require XPath value.
After you create and run the scraper task successfully, the posts are published with the content from the source feed. You can use these posts as they are, edit and publish them manually, or keep up to date by taking advantage of “Schedule” feature.
Finding the feed URL
To fill in “Source URL” field; some of the methods that can be used to find the web address of the source feed you want to populate content are as follows.
- The source site is controlled to see whether the standard mostly orange color feed icon is on the page. If this icon is available on the page, the web address it is redirected to is used as the feed URL.
- By adding “/feed/” to the end of the web address of the source site to which the content is intended to be pulled, it is checked whether the new web address is available. The feed URL is used if the resulting web address is valid.
- The source site’s page source code is viewed whether feed url is in the source. The feed is used as the URL if there is a web address found in the page source when searched for “RSS”, “Atom” or “Feed” (Control + F, or Command + F on a Mac).